この記事は、Competitive Programming Advent Calendar Div2012の12日目の記事として書きました。
0. はじめに
今回はマトロイドについて書きたいと思います。
マトロイドはGreedyとの関連でよく耳にします。では、そもそもマトロイドがGreedy性を持つのは何故でしょうか?実は、マトロイドは単に「Greedyの一例」として出て来るばかりでなく、「現在効率的なアルゴリズムが知られている問題の殆どはマトロイドが何かしら関わっている」と言える程にイイ構造を持っています。以前、以下のようなツイートをしました。
dpやってていつも思うのが、なんか凸凹してるなーと。凸凹し過ぎてdpじゃなきゃ解けないよな、みたいな感じ。マトロイドは凹んでるところがない凸なイメージ。だから、局所最適狙う貪欲法だけで最適解に辿り着ける。焼き鈍しなんて必要ない。
本記事では、この「マトロイドの凸なイメージ」をもう少し具体的に実感できるような内容を目指します。こうした営みは直接的には競プロの腕を上げることには繋がらないかもしれませんが、
- この問題は、なんかキレイだぞ………もしや、フローに落とせないかな???
- この最小手数問題は、最小手数を達成する手順の様相がバラバラだ。BFSなりするしかなさそう。。。
- この最大化問題は、色々試したけど規則性がありそうもない。DPなり半分全列挙なりするしかないようだ。
といった着想を産む効果があると思います。
<コンテンツ>
0. はじめに
1. マトロイドとは
2. 凸凹でも通用!DPのパワー!
3. Marathonではお馴染み、ローカルサーチ
3-1. ローカルサーチ
3-2. 凸構造
4. マトロイドの凸構造に迫る!
5. おわりに
1. マトロイドとは
まずは、マトロイドとは何ぞや?から始めます。
数学では、集合が与えられたときに、そこに何かしらの構造を入れることをよくやります。有名所だと、順序集合、位相空間、確率空間、群、…といった感じで、マトロイドもその仲間です。
まず、個の要素からなる有限集合
が与えられたとします。
の部分集合は
個あります。例えば、
= {1, 2, 3}なら、その部分集合は、{ {}, {1}, {2}, {3}, {1,2}, {1,3}, {2,3}, {1,2,3} }の8個です。それら1つ1つについて、「独立」と「従属」のどちらかに割り振り、「独立」に割り振られたモノの集合を
とします。この割り振り方が特別な条件を満たすとき、それをマトロイドと呼びます。
<マトロイドの定義>
有限集合とその部分集合の集合
が、以下の条件を満たすとき、(
,
)をマトロイドという。
- (A1) 空集合
について、
- (A2)
で、
ならば、
- (A3)
,
が存在して、
{e}
また、に含まれる集合は「独立」であるという。(|
|とは、
の要素数を表す)
なお、(A1)と(A2)を満たすモノは独立性システム、(A1)と(A3)を満たすモノはグリードイドと呼びます。

例えば、 = {1, 2, 3}として、以下のような感じです。
| ex.1 | 自明なマトロイド | |
| ex.2 | マトロイド | |
| ex.3 | マトロイド(上図のマトロイド) | |
| ex.4 | マトロイドでない(上図の独立性システム) | |
| ex.5 | マトロイドでない(上図のグリードイド) |
- ex.4は、{1,2}と{3]とを比較したときに、{3}に1,2のいずれを追加しても
- ex.5は、{1,2}の部分集合であるはずの{2}が
(なお、上図は、wikipediaの図を少し改造したモノです。)
「独立」「従属」といった用語からも分る通り、マトロイドは元々はベクトルの一次独立性を一般化する形で、Whitneyによって1935年に導入されました。実際、行列が与えられたとき、
の列ベクトルを
,
, …,
とすると、
= {
,
, …,
}、
= (
の部分集合のうち、一次独立なモノの集合)とすると、(
,
)はマトロイドとなります。これはベクトルマトロイドと呼ばれます。
無向グラフが与えられる。
の枝集合
とする
このとき、(,
)はマトロイドであり、グラフ的マトロイドと呼ばれる。
これがマトロイドであることの証明は、T.コルメン等著, 浅野哲夫等訳 : "アルゴリズムイントロダクション 改訂2版"にあります。
マトロイド上のGreedyアルゴリズム
さて、マトロイドの最も重要な性質は、Greedyアルゴリズムが適用できることです。以下のような問題を考えてみましょう。
Problem Statement
マトロイド(M, I)が与えられる。Mの各要素eについて、0以上の重みw(e)が与えられている。
このとき、Mの「独立」な部分集合Xのうち、各要素の重みの総和が最大となるモノについて、
その最大値を求めよ。
Examples
0)
M = {1, 2, 3}
I = { {}, {1}, {2}, {3}, {1,2}, {1,3}, {2,3} }
w = {4, 5, 6}
Returns : 11 ({2,3}としたときが最大です) 競プロの体裁になっていませんが御容赦下さい^^;
まず1つの観察として、重みはどれも0以上なのでなるべくの要素数は大きくしたいです。で、いきなりですが、この問題は以下のようなGreedyアルゴリズムで解くことができます。
1. X ← {}
2. res ← 0
3. (M, w)を、wの大きい順にソートする
4. for i ← 0 to M.size() do
5. e ← M[i]
6. if X∪{e}が「独立」 then
7. X ← X∪{e}
8. res ← res + w(e)
9. return res つまりは、の要素のうち、重み
が大きい順に見て行き、
に追加できるなら追加していくことを行います。このアルゴリズムを見て、最小全域木を求めるKruskal法を想起された方も多いと思います。実際、このGreedyアルゴリズムをグラフ的マトロイドに適用したものが、Kruskal法に他なりません。(但し、重み最大のところを、最小にする。)
このGreedyアルゴリズムを用いて解ける問題として、Kruskal法の他に、
- 単位時間ジョブスケジューリング問題(http://topcoder.g.hatena.ne.jp/spaghetti_source/20121103/1351911603参照)
- ベクトルマトロイドに用いる問題(SRM 526.5 DIV1 Hard)
があります。後者は、hirosegolfさんより紹介頂きました。
2. 凸凹でも通用!DPのパワー!
では、何故マトロイドはこのようなGreedyアルゴリズムが上手くいくのでしょうか?それを探る前に、少しDPの話をします。DPと言うと、
全探索だと間に合わないから、DPを考えないと…
のように、「全探索 vs DP」のような図式で語られがちです。しかし、DPでやっていることは結局全探索なのではないかと思います。というのは、
DPは、まとめられる処理をまとめて、同じ計算を行うムダをなくしているだけで、結局あり得る場合を、"全"て、"探索"していることには変わりない
からです。
それに対し、上のような「マトロイド上でのGreedyアルゴリズム」は、猪突猛進!最適解に向かって一直線に走っているのみです。あり得る場合を全て探索するようなことはしていません。この違いがどうして生まれるのかを考えるために、ナップサック問題を考えてみましょう。(蟻本の01ナップサック問題と全く同じ問題です。)
Problem Statement
n個の品物があり、それぞれの重さと価値は、wi, viで与えられます。
これらの品物の中から、重さの総和がWを超えないように選んだときの、
価値の総和の最大値を求めよ。
Constraints
・1 <= n <= 100
・1 <= wi, vi <= 100
・1 <= W <= 10000
Examples
0)
n = 6
(w,v) = {(2,3), (1,2), (3,6), (2,1), (1,3), (5,85)}
W = 8
Returns : 91 (2, 5番の品物を選んだときが最大です)この問題は以下のようなDPで解くことができます。なおこの解法は、蟻本のP.55のCOLUMNに記載されている解法と本質的に一緒ですが、後の説明の都合上、DPの状態の持ち方を僅かに変えています。どちらでも漸化式自体は変わりませんが、dpの初期条件とリターン部分がビミョーに変わります。
dp[i+1][j] := 0番目からi番目までの品物について、 重さの総和が"丁度j"となるように選んだときの価値の総和の最大値 として、 dpテーブル全体を-INFにセット dp[0][0] = 0 dp[i+1][j] = max(dp[i][j], dp[i][j-wi] + v[i]) return max(0<=j<=W)(dp[n][j])
上のDP漸化式は、ちゃんと実装するときは、j >= wiかどうかで場合分けが必要です。
ナップサック問題の凸凹な様相
さて、上のナップサック問題のExampleについて、実際にDPテーブルを書いてみましょう。

(品物は、(w,v) = {(2,3), (1,2), (3,6), (2,1), (1,3), (5,85)})
さて、このDP表を眺めているだけでも、かなりゴチャゴチャと色んな状況が現れているのが見てとれます。
- 漸化式の遷移状況がバラバラ!
- 青マス(dp[4][6])を見ると、dp[3][6] vs dp[3][4] + 1 → dp[3][4]の勝ち!
- 黄マス(dp[5][3])を見ると、dp[4][3] vs dp[4][2] + 3 → 同点!
- 赤マス(dp[6][9])を見ると、dp[5][9] vs dp[5][4] + 85 → dp[5][4] + 85の勝ち!
- これらの3パターンがバラバラに混在しています
- dp[4][6]とdp[4][7]とを見比べると、なんと逆転しています!!!
こうして見ると、「あー、なんかヤバそうな問題だなぁ…」と直感がはたらいて来ます。
ヤバそうというのは、「入力ケースによって色んなパターンが生まれて来て、とても規則性など見出せそうにない」という感じです。ですので結局、「DPなり半分全列挙なりするにせよ、あり得る場合の全体を探索しないといけない」という雰囲気を感じます。(枝刈りや分枝限定法のことは一旦置いときます…)。
探索のココロ
話は若干逸れますが、競プロを始めるに当たって最初の関門は、「探索」の考え方に馴染む部分ではないかと思います。逆に、問題を深く洞察することによって、探索は殆どしなくても陽的に解けてしまうこともあります。所謂、「数学ゲー」というヤツですね。例えば、
- 「1以上の整数Nが与えられたとき、それが2以上の2つの偶数の和として表すことができるか判定せよ」
とかは、数学ゲーの最もシンプルな例の1つと言えます。(Nが偶数かどうかを判定するだけです。N=2の場合がコーナーケースになりますが…)
他にも、蟻本の最初の方に出て来る、
も数学ゲーと言えるでしょう。これも、minを使った数式にはなりますが、明示的に解を書き下すことができます。
しかし、世の中の問題の多くは、このようなキレイな構造は持っていないことが殆どです。
規則性など見つかりそうもなく、入力ケースによって挙動がバラバラなので結局探索するしかない。僕は、競プロを始める前までは、「問題を解く」とは、「問題を陽的に解く」ことだと無意識のうちに思っていました。そして競プロの世界に入って、「問題が陽的に解けなくとも、解を出力するアルゴリズムを見出せば良い」という考え方を知り、感動して目からウロコだったのを覚えています。

話が大分逸れてしまいましたが、要するに、ナップサック問題は、規則性など見つかりそうもない凸凹した問題だということです。せっかくある山の頂上に辿り着いても、もっと高い山があるかもしれないのです。実際、ナップサック問題はNP-Hardであることが知られています。そんな凸凹な問題であっても何とか高速に全体像を把握しよう!!!その代表的な手法が、(SRM系コンテストでは)DPとか、半分全列挙とか、…という感じですね。
なお、具体的に探索スキルを学ぼう、と思うと、chokudaiさんの最強最速アルゴリズマー養成講座の各記事が面白かったです。
3. Marathonではお馴染み、ローカルサーチ
前章にて、ナップサック問題の凸凹感を書いてみました。同時に、こんな凸凹な空間全体を高速に駆け抜けてしまうDPのパワーにも触れました。しかし、凸凹空間を何とか扱うアルゴリズムはDPだけではありません。僕はまだあまり詳しくないのですが、Marathon Matchでは多彩な技が繰り広げられているだろうと思います。その中でも特に「ローカルサーチ(とそれを基にしたアルゴリズム)」はお馴染みですね。
3-1. ローカルサーチ
ローカルサーチは、別名「山登り法」とも言われます。
今、ある関数を最大化する問題を考えたいとします。関数は或る意味、山脈のようなモノと考えることができます。よって最大化問題は一種の山登りと考えられます。しかし普通の山登りと違い、「景色全体が見渡せるわけではなく、自分のすぐ近くしか見えない」という状況となっています。このすぐ近くのことを、「近傍」と呼びます。
この設定の下で、ローカルサーチとは、
- 「近傍」の中で現在の高さよりも高い場所が見つかれば、そこへ移動する
- 「近傍」の中で現在の高さよりも高い場所がなければ、現在の解を出力する
というアルゴリズム手法です。
「近傍」を上手く設定することがとても大切になって来ます。
ローカルサーチの困難
例えば上のような山脈において、頂上の木がある場所へ辿り着くことを考えてみましょう。このとき、例えば一度左下の一番低い山を登ってしまったとします。このとき、その山の頂上に辿り着いてしまったら、もう身動きが取れなくなってしまいます。この状態を、「ローカル最適に陥る」と言います。
この状況を克服するための改善策として、
- マルチスタートローカルサーチ(ローカルサーチのスタート地点を複数点設けます)
- 焼き鈍し法
- 遺伝的アルゴリズム
- タブーサーチ
などがあります。これらの詳細については、アドベントカレンダー24日に、nico_shindanninさんが焼き鈍し法についての記事を予定されているので、楽しみにしましょう。
3-2. 凸構造
さて、このローカルサーチ。山脈相手には色々と難しいが、1つの山が相手としたら、ローカル最適がそのままグローバル最適になります!そんな夢の手法を実現させてくれるのが凸構造です。
凸構造の何が嬉しいかって、「ローカルサーチするだけでグローバル最適解が求まる」だけではありません!「今いる地点の近傍により良い解がないならば、それはグローバル最適解であることが保証される」というのが著しい嬉しさです。
例えば、巡回セールスマン問題を考えてみます。最短っぽい経路が求まったとします。それで、コレが本当に最短であることをどうやって証明したらよいでしょうか???巡回セールスマン問題のような凸凹な問題は、最短経路を求めるどころか、最適性の判定すらままならない難問です。
4. マトロイドの凸構造に迫る!
さて、いよいよマトロイドの本質に迫って行きましょう。何故マトロイドは、あのようなGreedyアルゴリズムが適用できるのか?
マトロイドの定義を再掲しましょう。
<マトロイドの定義>
有限集合とその部分集合の集合
が、以下の条件を満たすとき、(
,
)をマトロイドという。
- (A1) 空集合
- (A2)
- (A3)
また、に含まれる集合は「独立」であるという。(|
|とは、
の要素数を表す)
マトロイドを、Greedyアルゴリズムとの関連で見るときにはこの定義がピッタリなのですが、ローカルサーチとの関連で見るときは少し書き換えた方が良いので、書き換えて行きます。
極大独立集合
さて、マトロイドの「独立」な集合のうち、もうこれ以上何を追加しても従属になってしまうような集合のことを「極大独立集合」と呼びます。
例えば、 = {1, 2, 3}として、以下のような感じです。
| 独立集合 | 極大独立集合 | |
| ex.1 | {} | |
| ex.2 | {1,2,3} | |
| ex.3 | {1,2} | |
| ex.4 | {1}と{2}と{3} | |
| ex.5 | {1,2}と{1,3} |
また、重要な例として、グラフ的マトロイドにおいては、「極大独立集合」とは、即ち、「全域木(森)」のことです。
上の例のように極大独立集合は複数あることもありますが、必ず「極大独立集合はどれもサイズが等しい」ことが簡単に示せます。も
も極大独立集合として、もし
であるならば、(A3)より、
には含まるが
には含まれないe
が存在して、
{e}もまた独立集合となります。しかし、これは
が極大独立集合であることに矛盾します。
また、極大独立集合のことを、マトロイドの基とも呼びます。以後、この用語を用います。
マトロイドの交換公理
上のマトロイドの定義では、の独立な部分集合を全て集めた集合
を持ち出して定義したのですが、代わりに、マトロイド
の「基」のみを全て集めた集合
を用いてマトロイドを以下のように定義することもできます!
<マトロイドの定義(基による定義)>
有限集合とその部分集合の集合
が、以下の条件を満たすとき、(
,
)をマトロイドという。
- (B1)
- (B2) 任意の
,
と、任意の e
に対し、ある f
が存在して、
- {e}
(集合,
に対して、
とは、
には含まれるが
には含まれない要素の集合を表す)
この(B2)を、マトロイドの交換公理と呼びます。
簡単に述べると、君と
君は同数の要素を持っています。このとき、
君は自分が持っていないモノで
君が持っているモノeを欲しがったとします。このとき、逆に
君は持っているけど
君は持っていないモノfが上手い具合にあって、
君と
君とでeとfとを交換することができます。交換しても、
君と
君は、相変わらず基のままなのです!!!!!
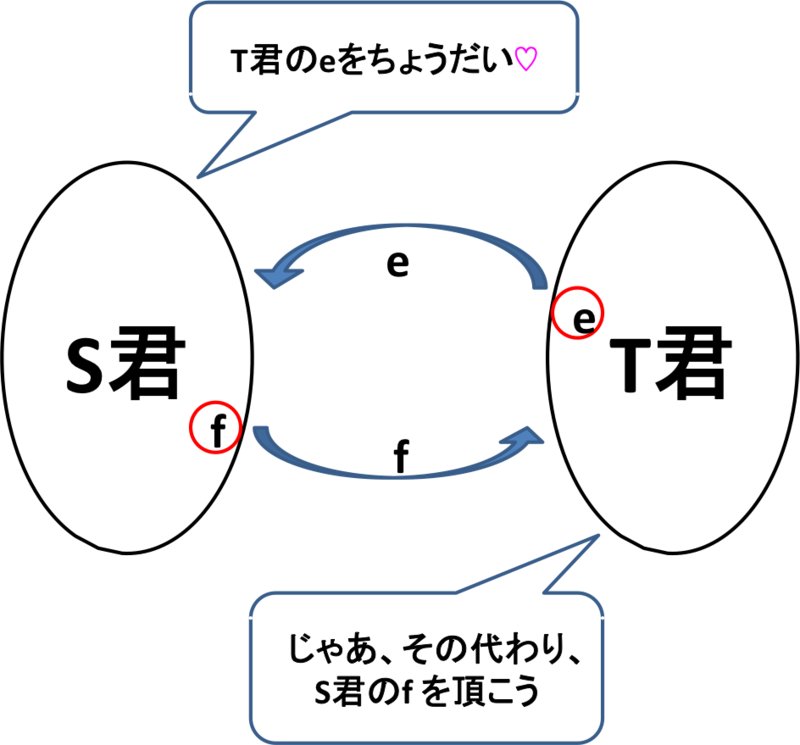
実は、最初のマトロイドの定義と、基によるマトロイドの定義は、本質的に全く等価であることが知られています。コレは決して自明ではありません。何故なら、基による定義の方が、圧倒的にイイ構造に思えるからです。上の定義で、「同時に」の部分が驚異的です。
今までマトロイドの2通りの定義を扱いましたが、実はまだまだ等価な言い換えがあります。代表的なモノに以下があります。
このうち、「独立集合による定義」と「基による定義2」について扱いました。「基による定義1」は、wikipediaの「基の族」の項目のところにあります。一見、「基による定義1」と「基による定義2」は殆ど同じに見えますが、よくよく見ると「基による定義2」の方が圧倒的に強いことを言っていることが分かります。4番目のランク関数については、5-1. 劣モジュラ関数にて簡単に触れたいと思います。なお、「基による定義2」以外の定義については、wikipediaに記載があります。
こうして見ると、マトロイドは本当に豊かな構造を持っていることが感じられます。
マトロイドの凸構造
さて、このマトロイドの交換公理。如何にも凸っぽい感じがするのではないでしょうか?そのイメージを明確にするためにもう少し"交換"によって何が起こるかを見てみましょう。下で書くことは、あくまでイメージでしかないのですが、こうしたイメージを持つことは意味ある営みだと思います。

上図のようなイメージです。S君もT君も「基」なので、同数の要素を持っています。そのうちの幾つかは被っている状態です。そして、始めはT君は持っているけどS君が持っていないモノは5個あります (これを S と T との距離とよぶことにします) が、ここで、(B2)の交換公理に従ってeとfとを交換します。
このとき、最初S君とT君はキョリ5だけ離れていたのに対し、交換後のS君は、T君とのキョリが1だけ縮まって 4 になります!!!
そして、交換後のS君も (交換後のT君も) 相変わらず「基」のままなのです!!!つまり、
最初S君もT君も「基の領域」に居たならば、交換後のS君とT君もやはり「基の領域」にいる!
ということを意味します。
ここで、そもそも凸って何?というのを思い出しましょう。

左図が凸集合の例で、右図が凸でない集合の例になります。集合Sが凸集合であるとは、Sに含まれる任意の2点x, yに対して、xとyとを結ぶ線分がSに含まれることを意味します。
然るにマトロイドの交換公理は、「基の領域」に含まれる任意のS君とT君に対して、S君とT君がお互いに少し内側に歩み寄っても、両者共に「基の領域」に含まれることを意味します。
こうして見ると、あくまで感覚的な話なのですが、マトロイドが凸構造を持つことが見えて来ます!「感覚的に」でなく「厳密に」、と思いたくもなるのですが、その必要はないのです。何故なら、マトロイドの交換公理自体をマトロイドの定義としたからです。我々としては、上のようなイメージを念頭に置いて、きっとイイことが示せるだろうと目論みつつマトロイドを定義して、凸であれば出て来るであろう「イイ性質」を見出していくことになります。
マトロイドの最適性条件
さて、いよいよマトロイドのGreedy性を解き明かしましょう。一応、マトロイドの最大重み集合を求める問題を再掲します。(基による定義に合わせて問題文を若干変えています)
Problem Statement
マトロイド(M, B)が与えられる。Mの各要素eについて、0以上の重みw(e)が与えられている。
このとき、Mの基Xのうち、各要素の重みの総和が最大となるモノについて、
その最大値を求めよ。
Examples
0)
M = {1, 2, 3}
B = { {1,2}, {1,3}, {2,3} }
w = {4, 5, 6}
Returns : 11 ({2,3}を選んだときが最大です)マトロイドの交換公理が示しているのは次のようなことです。
- あるマトロイド(
- 一方、最大重みな基を、
に、
- このとき、
- こうすることで、
これぞ、まさに、3. Marathonではお馴染み、ローカルサーチでも示したローカルサーチです!!!ローカル改善を繰り返して、最適解に近づこうとします。但し、実際にアルゴリズムを動かしている最中は理想の君の姿が分からないので、以下のようにします。
- ある
- そして
が「基」で、且つ「元のSよりも大きくなる」なら、
つまり、この場合でのローカルサーチの「近傍」とは、「からfを捨ててeを取り入れたモノ」ということになります。
そして、なんと!!!以下のことが成立します!!!
<マトロイドの最適性条件>
マトロイド(,
)に対し、ある基
が与えられたとすると、以下の2つは同値である。
この定理は、まさにマトロイドが凸構造を持つことを示しています!
の近傍に
より重みの大きいヤツはいない状況、つまり、ローカル最適な状況ならば、そのままグローバル最適になっているというわけです。このローカルサーチを少し効率良く実現しようとすると、Greedyアルゴリズムになります。
なお、5-2. 離散凸解析にて少し触れたいと思いますが、マトロイドはもっと広く、M凸集合と呼ばれる構造に一般化できます。上で述べた最適性条件は、M凸集合でも成立します。
6. おわりに
マトロイドの凸構造を軸に、様々なことを書き連ねて来ました。少し長くなってしまいましたが、ここまで読んで頂いた方に感謝の気持ちで一杯です。
僕は、「問題の持つ構造を深く洞察し、それに基づいて問題の解法を考える」という営みが大好きです。マトロイド程のイイ構造を持つモノはそうそうないですが、それでも、色々な問題の構造を活かして計算量を落としていくような作業がとても楽しいです。競プロ世界では、そんな楽しさが満ち溢れていてとても幸せです。
あと、本記事において、多少誤摩化してしまった部分があることもお詫びします。例えば、一貫して「凸構造」という言葉を使って来ましたが、本来は「凸集合」「凸関数」を明確に区別して考えるべきです。また、3. Marathonではお馴染み、ローカルサーチにて、「上に凸な関数」も凸関数と呼んでしまったのですが、本当は凸関数は「下に凸な関数」のことを指し、上に凸な関数は凹関数と呼ばれます。
何にせよ、この記事を書くことを通して、色々なことが頭の中で繋がって行ったのでとても楽しかったです。何か1つでも読んで頂いた方の心に残るモノがあったら嬉しいです。